Starwhale 数据集

设计概述
Starwhale Dataset 定位
Starwhale Dataset 包含数据构建、数据加载和数据可视化三个核心阶段,是一款面向ML/DL领域的数据管理工具。Starwhale Dataset 能直接使用 Starwhale Runtime 构建的环境,能被 Starwhale Model 和 Starwhale Evaluation 无缝集成,是 Starwhale MLOps 工具链的重要组成部分。
根据 Machine Learning Operations (MLOps): Overview, Definition, and Architecture 对MLOps Roles的分类,Starwhale Dataset的三个阶段针对用户群体如下:
- 数据构建:Data Engineer、Data Scientist
- 数据加载:Data Scientist、ML Developer
- 数据可视化:Data Engineer、Data Scientist、ML Developer
核心功能
- 高效加载:数据集原始文件存储在 OSS 或 NAS 等外部存储上,使用时按需加载,不需要数据落盘。
- 简单构建:既支持从 Image/Video/Audio 目录、json文件和 Huggingface 数据集等来源一键构建数据集,又支持编写 Python 代码构建完全自定义的数据集。
- 版本管理:可以进行版本追踪、数据追加等操作,并通过内部抽象的 ObjectStore,避免数据重复存储。
- 数据集分发:通过
swcli dataset copy命令,实现 Standalone 实例和 Cloud/Server 实例的双向数据集分享。 - 数据可视化:Cloud/Server 实例的 Web 界面中可以对数据集提供多维度、多类型的数据呈现。
- 制品存储:Standalone 实例能存储本地构建或分发的 swds 系列文件,Cloud/Server 实例使用对象存储提供集中式的 swds 制品存储。
- Starwhale无缝集成:
Starwhale Dataset能使用Starwhale Runtime构建的运行环境构建数据集。Starwhale Evaluation和Starwhale Model直接通过--dataset参数指定数据集,就能完成自动数据加载,便于进行推理、模型评测等环境。
关键元素
swds虚拟包文件:swds与swmp和swrt不一样,不是一个打包的单一文件,而是一个虚拟的概念,具体指的是一个目录,是 Starwhale 数据集某个版本包含的数据集相关的文件,包括_manifest.yaml,dataset.yaml, 数据集构建的Python脚本和数据文件的链接等。可以通过swcli dataset info命令查看swds所在目录。swds 是Starwhale Dataset 的简写。
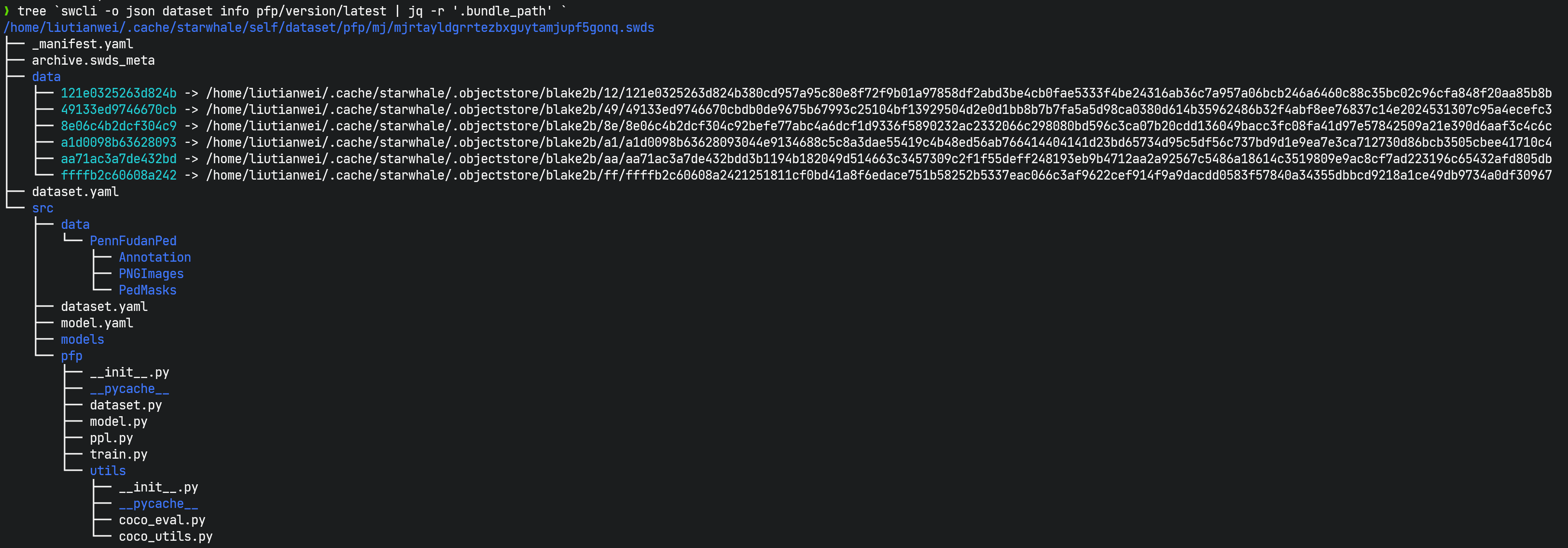
swcli dataset命令行:一组dataset相关的命令,包括构建、分发和管理等功能,具体说明参考CLI Reference。dataset.yaml配置文件:描述数据集的构建过程,可以完全省略,通过swcli dataset build参数指定,可以认为dataset.yaml是build命令行参数的一种配置文件表示方式。swcli dataset build参数优先级高于dataset.yaml。- Dataset Python SDK:包括数据构建、数据加载和若干预定义的数据类型,具体说明参考Python SDK。
- 数据集构建的 Python 脚本:使用 Starwhale Python SDK 编写的用来构建数据集的一系列脚本。
最佳实践
Starwhale Dataset 的构建是独立进行的,如果编写构建脚本时需要引入第三方库,那么使用 Starwhale Runtime 可以简化 Python 的依赖管理,能保证数据集的构建可复现。Starwhale 平台会尽可能多的内建开源数据集,让用户 copy 下来数据集后能立即使用。
命令行分组
Starwhale Dataset 命令行从使用阶段的角度上,可以划分如下:
- 构建阶段
swcli dataset build
- 可视化阶段
swcli dataset diffswcli dataset head
- 分发阶段
swcli dataset copy
- 基本管理
swcli dataset tagswcli dataset infoswcli dataset historyswcli dataset listswcli dataset summaryswcli dataset removeswcli dataset recover
Starwhale Dataset Viewer
目前 Cloud/Server 实例中 Web UI 可以对数据集进行可视化展示,目前只有使用 Python SDK 的DataType 才能被前端正确的解释,映射关系如下:
- Image:展示缩略图、放大图、MASK类型图片,支持
image/png、image/jpeg、image/webp、image/svg+xml、image/gif、image/apng、image/avif格式。 - Audio:展示为音频wave图,可播放,支持
audio/mp3和audio/wav格式。 - Video:展示为视频,可播放,支持
video/mp4、video/avi和video/webm格式。 - GrayscaleImage:展示灰度图,支持
x/grayscale格式。 - Text:展示文本,支持
text/plain格式,设置设置编码格式,默认为utf-8。 - Binary和Bytes:暂不支持展示。
- Link:上述几种多媒体类型都支持指定link作为存储路径。
Starwhale Dataset 数据格式
数据集由多个行组成,每个行成为为一个样本,每个样本包含若干 features ,features 是一个类 dict 结构,对key和value有一些简单的限制[L]:
- dict的key必须为str类型。
- dict的value必须是 int/float/bool/str/bytes/dict/list/tuple 等 Python 的基本类型,或者 Starwhale 内置的数据类型。
- 不同样本的数据相同key的value,不需要保持同一类型。
- 如果value是list或者tuple,其元素的数据类型必须一致。
- value为dict时,其限制等同于限制[L]。
例子:
{
"img": Image(
link=Link(
"123",
offset=32,
size=784,
_swds_bin_offset=0,
_swds_bin_size=8160,
)
),
"label": 0,
}
文件类数据的处理方式
Starwhale Dataset 对文件类型的数据进行了特殊处理,如果您不关心 Starwhale 的实现方式,可以忽略本小节。
根据实际使用场景,Starwhale Dataset 对基类为 starwhale.BaseArtifact 的文件类数据有两种处理方式:
- swds-bin: Starwhale 以自己的二进制格式 (swds-bin) 将数据合并成若干个大文件,能高效的进行索引、切片和加载。
- remote-link: 满足用户的原始数据存放在某些外部存储上,比如 OSS 或 NAS 等,原始数据较多,不方便搬迁或者已经用一些内部的数据集实现进行封装过,那么只需要在数据中使用 link,就能建立索引。
在同一个Starwhale 数据集中,可以同时包含两种类型的数据。